

Stopping Criteria for Decision tree Algorithm and tree Plots
Decision Tree is an algorithm build for Machine learning purposes which works on the concepts of dividing data into subsets. It means it works to give you subsets representing only one type of category or values within particular range. But there are certain drawback that need to be discussed.
There is a term used in machine Learning called Overfit Model. It is sort of model which is exceptionally well on the data which is used for training but unable to perform that well when tested over unknown set of values.
Why it happens ? It happens because of unregulated coefficients or training parameters while training your model. For example in Decision tree Classifier if the growth of tree is not regulated than it leads to Overfit model. As by default it will run behind Gini Index to make it 0.0 and in the process it will keep dividing the data into subsets to a kind of depth which leads to 100% accuracy because each data sample will get their best possible position. But the model becomes data specific and fails to perform well on unknown input values.
So we regulate the process of learning by using Stopping criteria which stops the learning by accepting some amount of error but not let the model overfit.
Here we will apply different stopping criteria and evaluate our model using accuracy and plot the tree grown during the course of training of our model using Decision Tree Algorithm.
Some Stopping Criteria are listed below:-
- max_depth
- max_leaf_nodes
- min_impurity_split
- min_samples_leaf
- min_samples_split
Let’s consider a toy dataset from sklearn. It’s a wine data set with 13 features representing three types of wines mentioned under class_0, class_1, class_2.
from sklearn.datasets import load_wine df = load_wine() print(df.keys()) print(df['feature_names']) print(df['target_names'])
#Output dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names']) ['alcohol', 'malic_acid', 'ash', 'alcalinity_of_ash', 'magnesium', 'total_phenols', 'flavanoids', 'nonflavanoid_phenols', 'proanthocyanins', 'color_intensity', 'hue', 'od280/od315_of_diluted_wines', 'proline'] ['class_0' 'class_1' 'class_2']
import pandas as pd #Features X = pd.DataFrame(df['data'], columns = df['feature_names']) #Labels Y = df['target'] from sklearn.model_selection import train_test_split xtrain,xtest,ytrain,ytest = train_test_split(X,Y)
At first we will train our model ideally without using any stopping criteria. It results into a model as shown below. Accuracy on known set of data is 100% and for unknown data samples its restricted at 93%. It shows some sort of overfit model which is quite efficient if known values are passed for prediction but not so on unknown feature inputs.
from sklearn.tree import DecisionTreeClassifier
dmodel_0 = DecisionTreeClassifier()
dmodel_0.fit(xtrain,ytrain)
print('Training accuracy',dmodel_0.score(xtrain,ytrain))
print('Testing accuracy',dmodel_0.score(xtest,ytest))#Output Training accuracy 1.0 Testing accuracy 0.9333333333333333
Now we can plot our training tree as shown below which is not restricted by any condition and grows till it gets 0.0 Gini Index for each subset.
from sklearn.tree import export_graphviz dot_data = export_graphviz(dmodel_0, feature_names = xtrain.columns) from IPython.display import Image import pydotplus graph = pydotplus.graph_from_dot_data(dot_data) Image(graph.create_png())
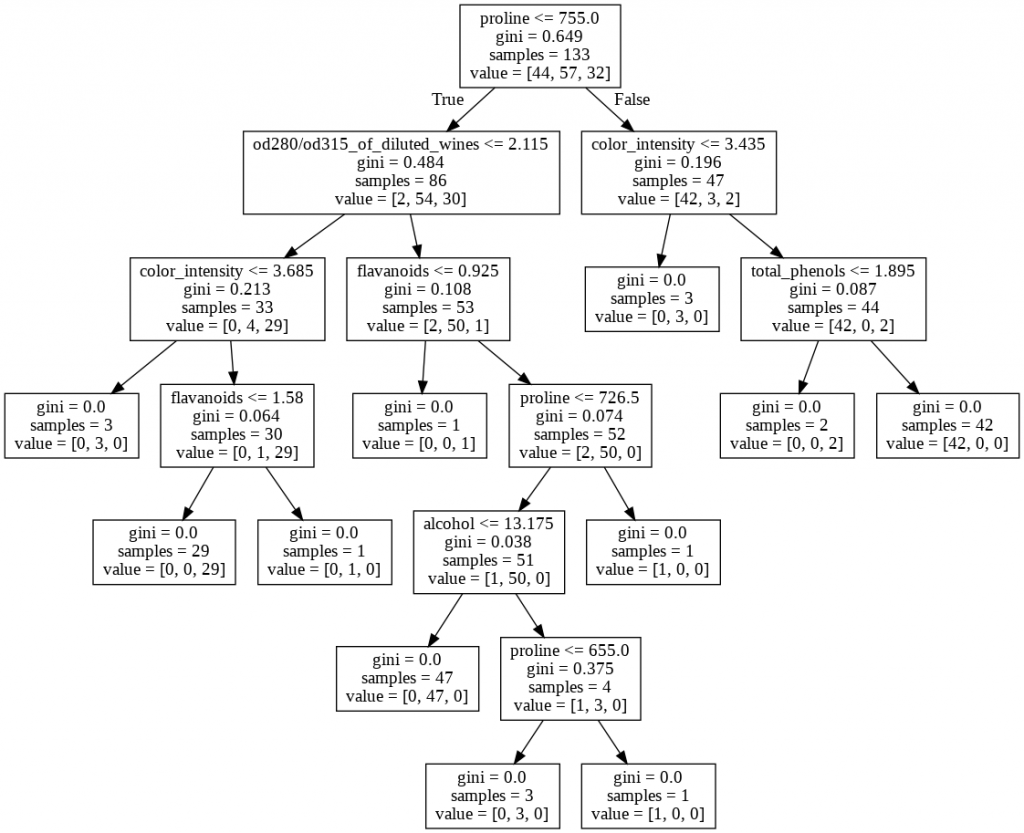
Poor Alice! It was as much as she could do, lying down on one side, to look through into the garden with one eye; but to get through was more hopeless than ever: she sat down and began to cry again.
Lewis Carroll
Apply Stoping Criteria
Now for next 6 developed model we will apply six kinds of stopping criteria to restrict the growth of tree and accepting some sort of loss during training, which can avoid overfit condition.
Max Depth – It will control the tree growth and restrict it upto a defined label only which in turn avoid a situation where model is having perfect subset for each feature and category. In this case we can see Training and Testing accuracy are almost close which shows the model is not overfit model
from sklearn.tree import DecisionTreeClassifier
dmodel_1 = DecisionTreeClassifier(max_depth=3)
dmodel_1.fit(xtrain,ytrain)
print('Training accuracy',dmodel_1.score(xtrain,ytrain))
print('Testing accuracy',dmodel_1.score(xtest,ytest))#Output Training accuracy 0.9774436090225563 Testing accuracy 0.9777777777777777
from sklearn.tree import export_graphviz dot_data = export_graphviz(dmodel_1, feature_names = xtrain.columns) from IPython.display import Image import pydotplus graph = pydotplus.graph_from_dot_data(dot_data) Image(graph.create_png())
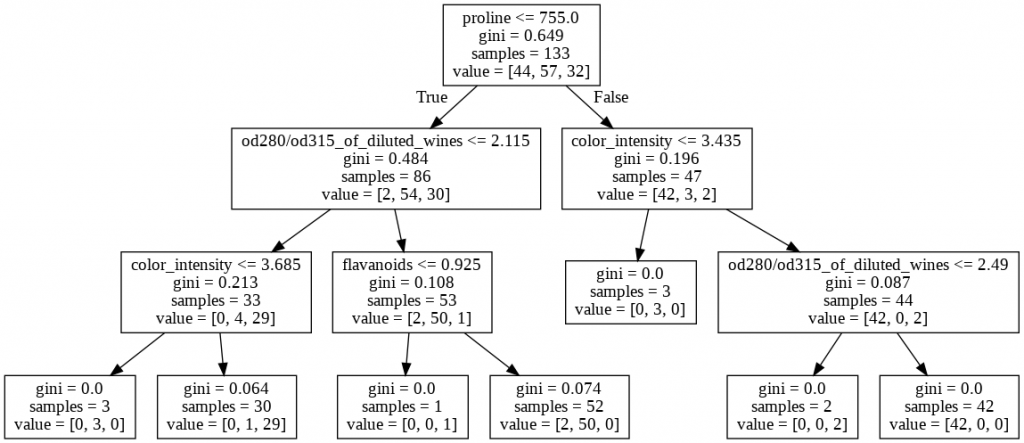
Maximum Leaf Node: – It is used to define the acceptable numbers of leaf nodes. It means we restricts the growth of number of terminating nodes which decides the predicted value. It also helps in controlling the size of tree. Here testing accuracy is same as model_0 which confirms the first model what we created first was overfit as with the increase of size of model only training accuracy gets benefited and touches 100% and testing accuracy remains at 93%
from sklearn.tree import DecisionTreeClassifier
dmodel_2 = DecisionTreeClassifier(max_leaf_nodes = 7)
dmodel_2.fit(xtrain,ytrain)
print('Training accuracy',dmodel_2.score(xtrain,ytrain))
print('Testing accuracy',dmodel_2.score(xtest,ytest))Training accuracy 0.9774436090225563 Testing accuracy 0.9333333333333333
from sklearn.tree import export_graphviz dot_data = export_graphviz(dmodel_2, feature_names = xtrain.columns) from IPython.display import Image import pydotplus graph = pydotplus.graph_from_dot_data(dot_data) Image(graph.create_png())

Minimum Impurity for split: – It looks out of losses in each node. Here it is making sure that the further division of nodes needs minimum loss or Gini Index of 0.2. If Gini Index reaches below 0.2 then it can accepts that model with no further tree growth and uses the majority in leaf nodes for predictions.
from sklearn.tree import DecisionTreeClassifier
dmodel_3 = DecisionTreeClassifier(min_impurity_split=0.2)
dmodel_3.fit(xtrain,ytrain)
print('Training accuracy',dmodel_3.score(xtrain,ytrain))
print('Testing accuracy',dmodel_3.score(xtest,ytest))Training accuracy 0.9323308270676691 Testing accuracy 0.8444444444444444
from sklearn.tree import export_graphviz dot_data = export_graphviz(dmodel_3, feature_names = xtrain.columns) from IPython.display import Image import pydotplus graph = pydotplus.graph_from_dot_data(dot_data) Image(graph.create_png())

Minimum Samples in leaf Node: – It checks for number of samples at end node and stops the further division of a node once the minimum sample criteria reached.
from sklearn.tree import DecisionTreeClassifier
dmodel_4 = DecisionTreeClassifier(min_samples_leaf=5)
dmodel_4.fit(xtrain,ytrain)
print('Training accuracy',dmodel_4.score(xtrain,ytrain))
print('Testing accuracy',dmodel_4.score(xtest,ytest))Training accuracy 0.924812030075188 Testing accuracy 0.8444444444444444
from sklearn.tree import export_graphviz dot_data = export_graphviz(dmodel_4, feature_names = xtrain.columns) from IPython.display import Image import pydotplus graph = pydotplus.graph_from_dot_data(dot_data) Image(graph.create_png())

Minimum number of samples for splitting: – It checks out for internodes and decides the splitting on the basis of condition defined. For example in this case a node will split only if it has a minimum number of 4 samples present. If a node is having less then 4 sample it will not divide further.
from sklearn.tree import DecisionTreeClassifier
dmodel_5 = DecisionTreeClassifier(min_samples_split=4)
dmodel_5.fit(xtrain,ytrain)
print('Training accuracy',dmodel_0.score(xtrain,ytrain))
print('Testing accuracy',dmodel_0.score(xtest,ytest))Training accuracy 0.9924812030075187 Testing accuracy 0.9555555555555556
from sklearn.tree import export_graphviz dot_data = export_graphviz(dmodel_5, feature_names = xtrain.columns) from IPython.display import Image import pydotplus graph = pydotplus.graph_from_dot_data(dot_data) Image(graph.create_png())
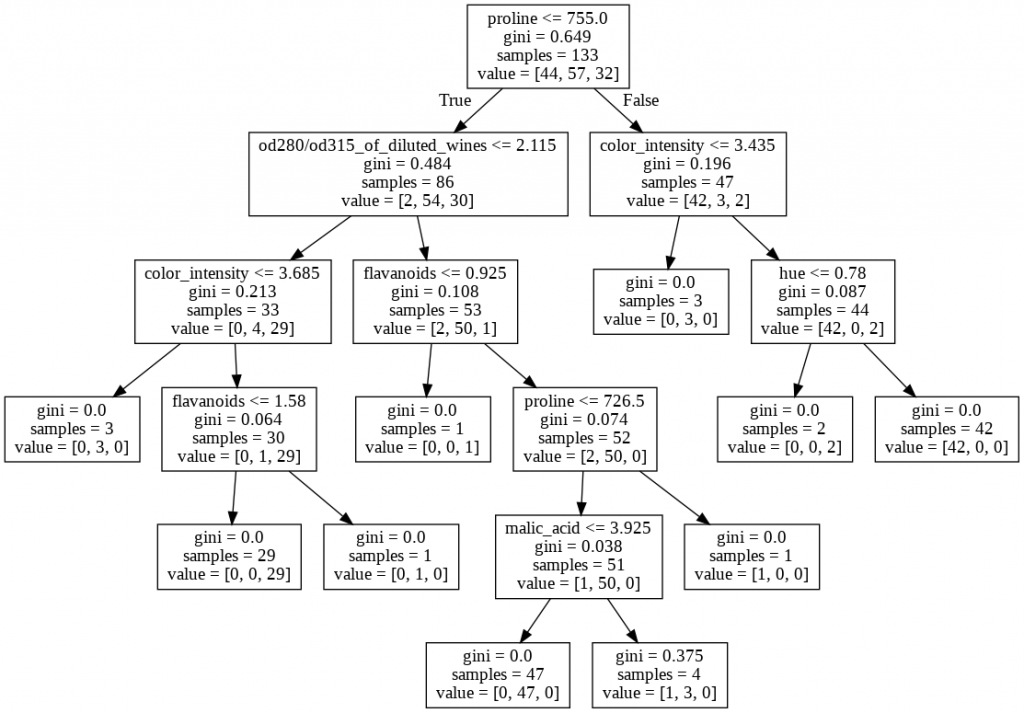
Multiple Stopping Criteria: – We can apply multiple stopping criteria if it works well with our data set as follows.
from sklearn.tree import DecisionTreeClassifier
dmodel_6 = DecisionTreeClassifier(max_depth=3 , min_samples_leaf=5)
dmodel_6.fit(xtrain,ytrain)
print('Training accuracy',dmodel_0.score(xtrain,ytrain))
print('Testing accuracy',dmodel_0.score(xtest,ytest))Training accuracy 0.924812030075188 Testing accuracy 0.8444444444444444
from sklearn.tree import export_graphviz dot_data = export_graphviz(dmodel_6, feature_names = xtrain.columns) from IPython.display import Image import pydotplus graph = pydotplus.graph_from_dot_data(dot_data) Image(graph.create_png())

Conclusion: – If we don’t regulate a machine learning process then in the course of learning using some dataset a model tries to learn everything and achieves 100% accuracy over some specific data set which intern creates a overfit model.
In the case discussed above the model represented by dmodel_1, dmodel_2 and model_5 can be trusted more during the prediction as they are having less difference between training and validation accuracy and they are not even abnormal grown.
Thanks for your reading. Suggestions are always welcome. Keep Learning…