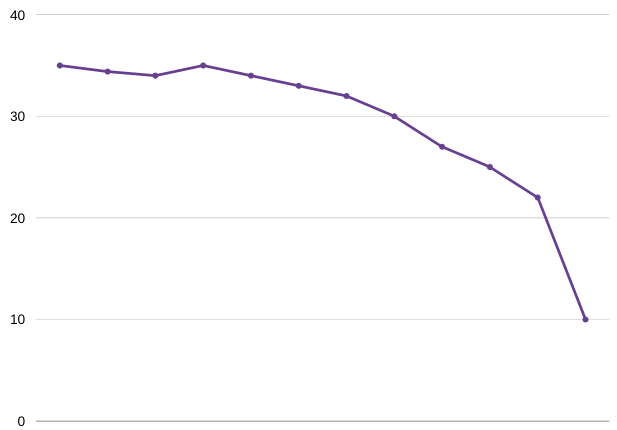
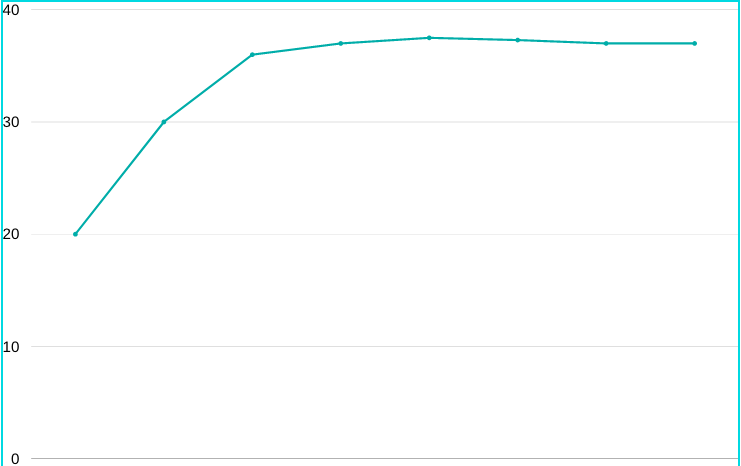
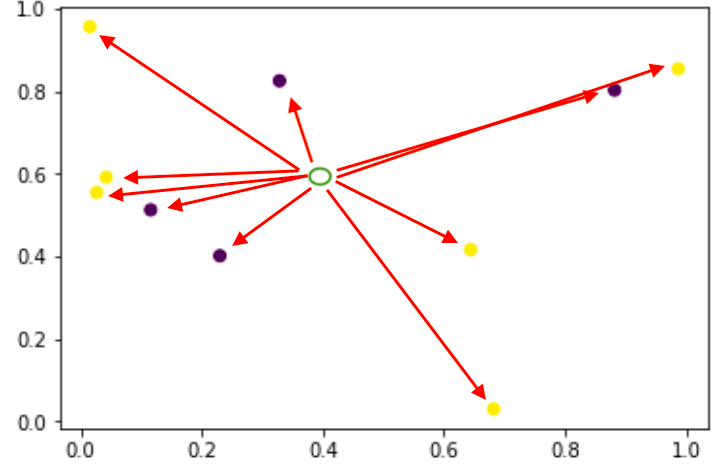
Machine Learning is an interdisciplinary field drawing from various information sciences such as computer science, statistics, mathematics, and engineering. According to Tom Mitchell, the author of Machine Learning, it is “the field of machine learning is concerned with the question of how to construct computer programs that automatically improve with experience.” This short definition is […]

Machine Learning
ML Algorithms