
KNN Algorithm and Maths behind
KNN or K – Nearest Neighbours is one the powerful algorithm used in classification based problems to successfully make categorical predictions. Scikit-Learn gives us built in library to use and make the process easier for us if we are having data. But here we will write KNN code mathematically without any inbuilt library to figure out the concept working behind.
It will be purely mathematical intuition of KNN algorithm. So let’s start.
What is KNN ?
KNN is an algorithm use to develop machine learning model in case of classification or categorical predictions. For example if we are having a data represent two category as ‘0’ and ‘1’ then we can use this algorithm to make predictions for some unknown feature value.
Let’s define a data with two features and one label. I am using random values for features and labels.
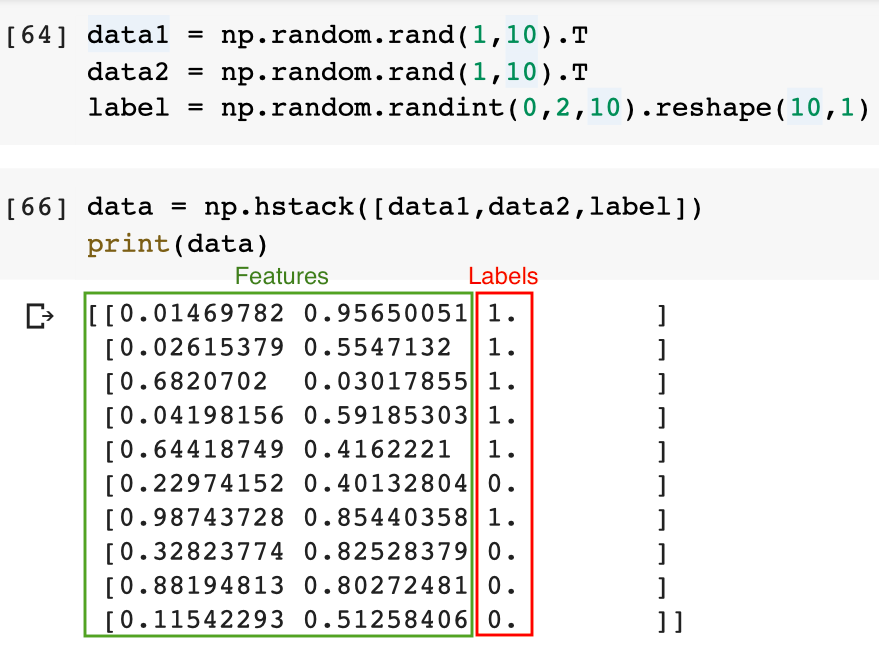
Here the data element in green box is considered as Features or independent variable and the red colour box is representing the dependent variable or label column. Lets plot the same on X and Y cordinates.
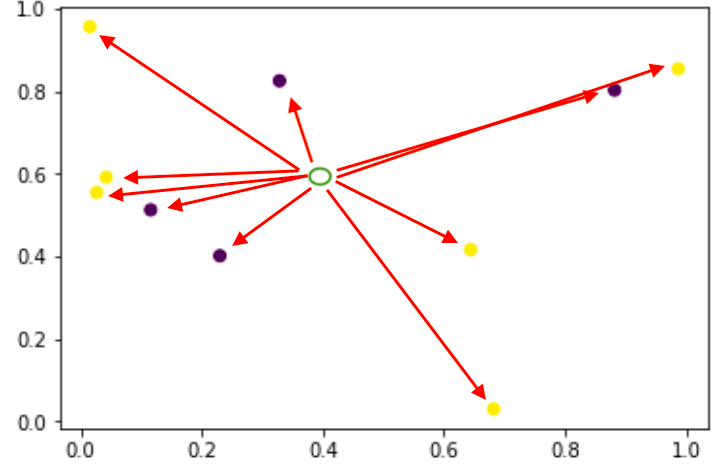
In this case we can see there are two kinds of dots are present. Purple and yellow are representing two kinds of categorical value on the dataset. category 1 is represented by yellow colour dots and category 2 is represented by purple colour one.
When some unknown input having only features where label need to be predicted came into the frame like a green colour circle then classification algorithm plays its role. For example KNN is used to make prediction by taking into reference of K-Nearest Neighbours. For example if we define the value K to be 5 then KNN will calculate the minimum distance between the unknown feature input and all known and existing data points using Euclidean distance formula as mentioned below.
Suppose there are two point (x1,y1) and (x2,y2) then we calculate the distance between these points using the formula given below.
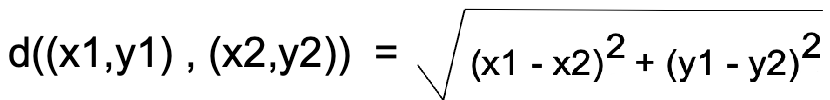
So, for a data containing 10 samples we will have 10 distances which will be compared and sorted to select 5 data points (as per k defined) and labels in majority out of those 5 will be considered as predicted value unknown input point. i.e if out of 5 nearest if 3 or 4 or 5 points are purple and rests are yellow then prediction for green dot is purple i.e 0.
Machine Learning is the field of study that gives ability to a computer to learn without being explicitly programmed.
Arthur L. Samuel
Let’s understand the mathematical intuition
We will first create a function to calculate the distance of each existing point from unknown feature value and sort it for the convenience of picking the 5 nearest one.
from math import sqrt
def my_knn(data , u_value):
distances = []
for row in data:
d = 0
for i in range(len(u_value)):
d += (u_value[i] - row[i])**2
distances.append((row , sqrt(d)))
distances.sort(key=lambda dis: dis[1])
return distancesHere to trigger this function we need two parameter such that parameter one is the existing data value and parameter 2 is the input value for which we need to predict label.
#Datas for training the model
data = data
#Unknown value for making prediction
u_value = np.array([np.random.rand(1),
np.random.rand(1)]).ravel()
print(u_value)[0.54187874 0.52071135]
Now trigger the function my_knn to get the sorted distances of u_value from all existing data points.
d = my_knn(data,u_value) print(d)
[(array([0.64418749, 0.4162221 , 1. ]), 0.14623639801220625), (array([0.22974152, 0.40132804, 0. ]), 0.3341886005499895), (array([0.32823774, 0.82528379, 0. ]), 0.37203070173294633), (array([0.11542293, 0.51258406, 0. ]), 0.4265332442677913), (array([0.88194813, 0.80272481, 0. ]), 0.4417904247318705), (array([0.04198156, 0.59185303, 1. ]), 0.5049339810697214), (array([0.6820702 , 0.03017855, 1. ]), 0.5101725992408717), (array([0.02615379, 0.5547132 , 1. ]), 0.5168446030777414), (array([0.98743728, 0.85440358, 1. ]), 0.5566623067270683), (array([0.01469782, 0.95650051, 1. ]), 0.6839823900980749)]
Now we can define a function to make predictions for feature in u_value by sorting first 5 rows in the array d and figuring out the maximum count of labels among them.
def prediction(u_value):
p = []
neighbors = []
k = 5
d = my_knn(dataset , u_value)
for i in range(k):
neighbors.append(d[i][0])
for row in neighbors:
p.append(row[-1])
print(max(p , key=p.count))
print(neighbors)Now trigger the prediction function to make predictions.
print('Unknown value for making prediction',u_value)
prediction(u_value)Unknown value for making prediction [0.54187874 0.52071135] Prediction is: 0.0 5 Nearest Neighbors are [array([0.64418749, 0.4162221 , 1. ]), array([0.22974152, 0.40132804, 0. ]), array([0.32823774, 0.82528379, 0. ]), array([0.11542293, 0.51258406, 0. ]), array([0.88194813, 0.80272481, 0. ])]
Here we can see out of 5 nearest neighbours 4 or majority is 0 and thus the prediction made is 0 or purple.
Complete Code snippet is given below.
data1 = np.random.rand(1,10).T
data2 = np.random.rand(1,10).T
label = np.random.randint(0,2,10).reshape(10,1)
data = np.hstack([data1,data2,label])
print(data)
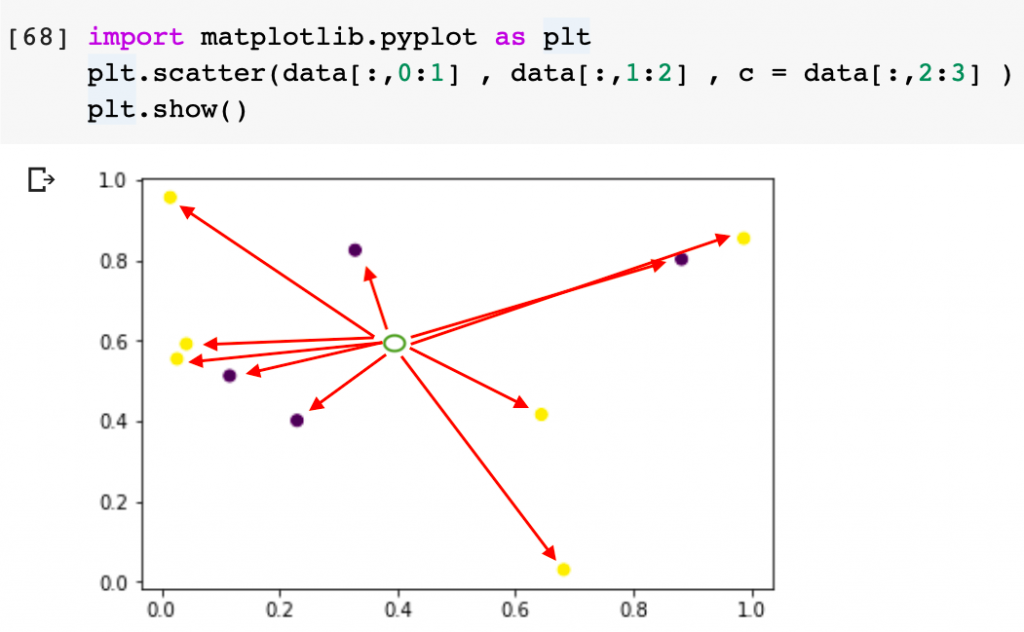
import matplotlib.pyplot as plt
plt.scatter(data[:,0:1] , data[:,1:2] , c = data[:,2:3] )
plt.show()
from math import sqrt
def my_knn(data , u_value):
distances = []
for row in data:
d = 0
for i in range(len(u_value)):
d += (u_value[i] - row[i])**2
distances.append((row , sqrt(d)))
distances.sort(key=lambda dis: dis[1])
return distances
data = data
u_value = np.array([np.random.rand(1),np.random.rand(1)]).ravel()
print(u_value)
d = my_knn(data,u_value)
d
def prediction(u_value):
p = []
neighbors = []
k = 5
d = my_knn(data , u_value)
for i in range(k):
neighbors.append(d[i][0])
for row in neighbors:
p.append(row[-1])
print('Prediction is:' ,max(p , key=p.count))
print('5 Nearest Neighbors are',neighbors)
print('Unknown value for making prediction',u_value)
prediction(u_value)KNN using Scikit-Learn
We can solve the same problem in just three line of code using KNN inbuilt class as KNeighborsClassifier with Scikit_Learn Library.
from sklearn.neighbors import KNeighborsClassifier
knmodel = KNeighborsClassifier(5)
knmodel.fit(data[:,0:2] , data[:,2:3])
print('Predictd Label:', knmodel.predict([u_value]))Predictd Label: [0.]
Thanks for your Time. Hoping for some feedback. Keep Learning……