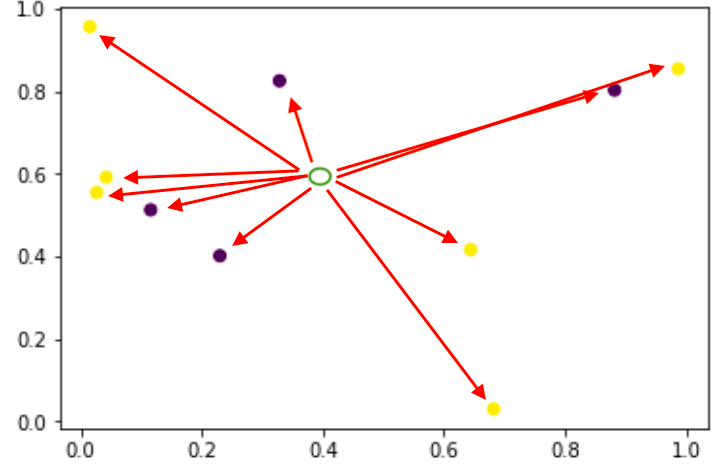
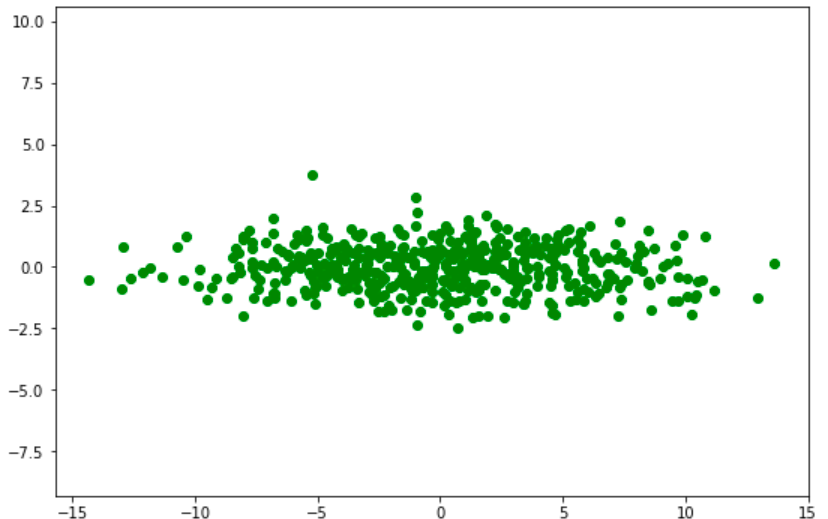
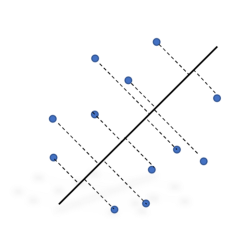
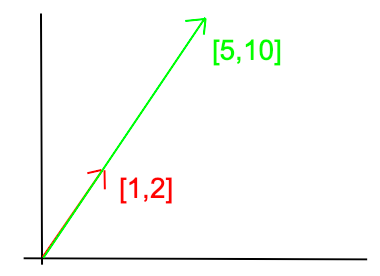
Pandas is one of the powerful library used in python for data science and analysis. It has n-number of functions, methods and attributes, which are comparatively easy in syntax and flexible in nature. So a data scientist or any one who wants certain insights from any huge set of data prefers it and let their […]

Data Analysis
Data Science Libraries